
Block all S3 access! Switch CloudFront to origin access identity
S3 buckets with public permissions at the bucket or object level expose organizations to potential data breaches. Numerous such exposures have been reported in the media, making hundreds of millions of records of personal information, financial data, government secrets, credentials, and proprietary business information available to anyone scanning the web or the global S3 namespace for names of improperly configured buckets.
In late 2018, AWS announced Block Public Access, which allows public ACLs to be denied or ignored at the bucket or account level, meaning that even if a software component or person mistakenly creates a bucket or object with a public ACL, you’re still protected.
The AWS feature announcement for Block Public Access makes it clear that public buckets are meant to be used for web hosting. However, the most risk reduction comes from turning on Block Public Access at the account level, which would also disable the use of S3 web hosting. Buckets created through the console may default to having Block Public Access turned on, but programmatically created buckets don’t, so either every bucket addition needs to be reviewed and checked for these settings, or you can just turn it on at the account level and move away from S3 web hosting as a feature.
Fortunately CloudFront can be used to fairly easily expose private S3 objects to the web using an origin access identity, but in order to set headers or perform redirects or CORS, you’ll need a Lambda@Edge function because those won’t be coming from the S3 web host. I’ll show you how to set the whole thing up with Terraform.
The architecture we’ll be implementing looks like this:
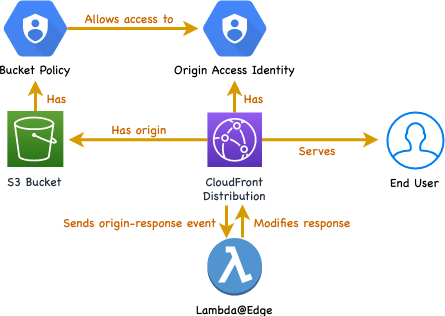
Terraform quick start
I’ll be using Terraform for these examples. If you haven’t used it before, here’s enough to be dangerous. Install Terraform, and Have an AWS credentials profile for a dev account. Put the following into main.tf:
provider "aws" {
version = "~> 2.0"
region = "us-east-1"
}Run terraform init, which will download the Terraform AWS provider. Run terraform plan and make sure there are no errors. Now you can create AWS resources with Terraform.
Deploying Lambda with Terraform
For a large-scale Lambda deployment, Terraform would not be my first choice; it’s a low level tool with no framework for serverless development. Since a Lambda@Edge function for setting headers is a single, short function with no modules or dependencies, it’s pretty easy to do with Terraform. If you have an existing serverless deployment, you could add the function to that, or keep it in Terraform so it’s next to the CloudFront config.
Here’s our function to set some headers. This is taken directly from the AWS Blog.
exports.handler = (event, context, callback) => {
const response = event.Records[0].cf.response
const headers = response.headers
headers['strict-transport-security'] = [
{ key: 'Strict-Transport-Security', value: 'max-age=63072000; includeSubdomains; preload' }
]
headers['content-security-policy'] = [
{
key: 'Content-Security-Policy',
value: "default-src 'none'; img-src 'self'; script-src 'self'; style-src 'self'; object-src 'none'"
}
]
headers['x-content-type-options'] = [{ key: 'X-Content-Type-Options', value: 'nosniff' }]
headers['x-frame-options'] = [{ key: 'X-Frame-Options', value: 'DENY' }]
headers['x-xss-protection'] = [{ key: 'X-XSS-Protection', value: '1; mode=block' }]
headers['referrer-policy'] = [{ key: 'Referrer-Policy', value: 'same-origin' }]
callback(null, response)
}Save this as headers.js.
Add the following to main.tf to zip the Lambda source code and create the Lambda along with the necessary permissions. I’m using the AWS managed service role for Lambda (AWSLambdaBasicExecutionRole) for simplicity.
data "archive_file" "lambda_zip" {
type = "zip"
source_file = "headers.js"
output_path = "headers.zip"
}
data "aws_iam_policy_document" "lambda_assume_role_policy" {
statement {
actions = ["sts:AssumeRole"]
principals {
type = "Service"
identifiers = ["lambda.amazonaws.com", "edgelambda.amazonaws.com"]
}
}
}
resource "aws_iam_role" "lambda_service_role" {
name = "lambda_service_role"
assume_role_policy = "${data.aws_iam_policy_document.lambda_assume_role_policy.json}"
}
resource "aws_iam_role_policy_attachment" "sto-readonly-role-policy-attach" {
role = "${aws_iam_role.lambda_service_role.name}"
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
}
resource "aws_lambda_function" "edge_headers" {
filename = "headers.zip"
function_name = "edge_headers"
role = "${aws_iam_role.lambda_service_role.arn}"
handler = "headers.handler"
source_code_hash = "${data.archive_file.lambda_zip.output_base64sha256}"
runtime = "nodejs10.x"
publish = true
}
resource "aws_lambda_permission" "allow_cloudwatch" {
statement_id = "AllowExecutionFromCloudWatch"
action = "lambda:InvokeFunction"
function_name = "${aws_lambda_function.edge_headers.function_name}"
principal = "events.amazonaws.com"
}You’ll need to run terraform init again since archive is a module it has to download. Then terraform plan and terraform apply to publish the function.
Deploying S3 and CloudFront with Terraform
Go ahead and add an S3 bucket.
resource "aws_s3_bucket" "web_distribution" {
bucket = "example"
acl = "private"
}Since the bucket namespace is global, change example to something unique right away.
CloudFront will have access to the private bucket contents through an origin access identity. This doesn’t require any parameters, though you can add a comment if you want. It’s possible to use one identity that has access to all your web buckets and is shared among CloudFront distributions, but here I’m creating one along with my bucket and CloudFront distribution to link just the two of them together.
resource "aws_cloudfront_origin_access_identity" "web_distribution" {
}The origin access identity will have access to the bucket through a bucket policy. You can define policies as raw JSON in here-docs if you want; I’m doing it in Terraform’s HCL syntax here just for consistency.
data "aws_iam_policy_document" "web_distribution" {
statement {
actions = ["s3:GetObject"]
principals {
type = "AWS"
identifiers = ["${aws_cloudfront_origin_access_identity.web_distribution.iam_arn}"]
}
resources = ["${aws_s3_bucket.web_distribution.arn}/*"]
}
}
resource "aws_s3_bucket_policy" "web_distribution" {
bucket = "${aws_s3_bucket.web_distribution.id}"
policy = "${data.aws_iam_policy_document.web_distribution.json}"
}Finally, the CloudFront distribution:
resource "aws_cloudfront_distribution" "web_distribution" {
enabled = true
is_ipv6_enabled = true
wait_for_deployment = false
default_root_object = "index.html"
price_class = "PriceClass_100"
origin {
domain_name = "${aws_s3_bucket.web_distribution.bucket_regional_domain_name}"
origin_id = "web_distribution_origin"
s3_origin_config {
origin_access_identity = "${aws_cloudfront_origin_access_identity.web_distribution.cloudfront_access_identity_path}"
}
}
default_cache_behavior {
allowed_methods = ["GET", "HEAD", "OPTIONS"]
cached_methods = ["GET", "HEAD", "OPTIONS"]
target_origin_id = "web_distribution_origin"
forwarded_values {
query_string = true
cookies {
forward = "none"
}
headers = ["Origin"]
}
viewer_protocol_policy = "redirect-to-https"
min_ttl = 0
default_ttl = 3600
max_ttl = 86400
lambda_function_association {
event_type = "origin-response"
lambda_arn = "${aws_lambda_function.edge_headers.qualified_arn}"
include_body = false
}
}
viewer_certificate {
cloudfront_default_certificate = true
}
restrictions {
geo_restriction {
restriction_type = "none"
}
}
}After another terraform apply, you’ll have a CloudFront distribution in an “in progress” state. Go get coffee. Setting wait_for_deployment to false means terraform will exit as soon as it’s made all the updates to AWS API objects and won’t poll for the distribution to become ready, which can take 15 to 20 minutes; you can watch this in the AWS console or with the CLI (aws cloudfront wait). You may have to leave wait_for_deployment enabled if you have other resources in your Terraform stack that depend on outputs of the CloudFront resource.
Next you’ll need to upload an index.html to your bucket, empty or with some dummy content.
After the CloudFront distribution is ready, try it out using the randomly generated default URL and inspect the headers; all the ones set in the Lambda code above should be there.
If you want to tear down these resources, you can use terraform destroy, but there are two things to keep in mind. The S3 bucket needs to be emptied before it can be deleted. And the Lambda function, once it’s attached to a CloudFront distribution, goes into a state where it cannot be deleted until it is detatched from all distributions it’s attached to and several hours have passed after that. If you want to remove it from your Terraform stack without waiting, the only way I’ve found is to use terraform state rm to make Terraform stop tracking the function and then clean it up by hand later.
Taking it to production
This is all an abbreviated example. The resources above are actually not bad; we’re following least privilege with all the permissions. But various other parts aren’t mentioned here at all, like Route 53 and ACM setup for CloudFront to put it on an actual domain. I’ve also excluded comments and tagging and chosen default TTLs.
The biggest changes I would consider for production would be in the Terraform department. Assuming you have multiple web distributions, figure out what is consistent & variable among them and put together a Terraform module with appropriate parameters. Note that the Lambda can be shared among distributions (assuming you don’t want unique behaviors for each) so it can be declared once outside of the CloudFront module.